FFT 实现快速卷积时,为什么会出现混叠?(一)如何用 Overlap-Add 解决?
很多工程师第一次使用 FFT 实现快速卷积时,都会默认认为“时域卷积 = FFT 乘法 + IFFT”,结果仿真一跑,分块边界附近却出现了明显失真。问题通常不在 FFT 本身,而在于:频域直接相乘再 IFFT,天然对应的是循环卷积,不是线性卷积。
如果没有处理好块边界和零填充,线性卷积尾部就会折返到块前部,形成时域混叠。对于长序列分块处理,这个问题会在每个块边界重复出现。
本文围绕一个可复现的 Python 仿真,把这个过程分成 4 个问题讲清楚:
- 为什么 FFT 实现快速卷积时会出现混叠现象,原理是什么?
- 结合仿真说明混叠现象是怎么混叠的?
- 结合仿真说明 overlap-add 方法是怎么解决这个问题的?
- 简要解释一下 OLA 和 WOLA 的区别。
下一期继续展开讲它的姊妹方法 overlap-save。本文完整的仿真代码放在个人网站VoxWorking上了,大家有兴趣免费自取即可。资源库 · VoxWorking
1. 为什么 FFT 实现快速卷积时会出现混叠现象,原理是什么?
我们熟悉的卷积定理是:
y[n] = x[n] * h[n]
<=>
Y[k] = X[k] H[k]
但这个公式在数值实现时有一个非常容易忽略的前提:
- 如果直接对长度为
N的序列做N点 DFT,再做频域相乘、IFFT 回来,得到的是 N 点循环卷积。 - 而在滤波、系统响应、FIR 实现中,我们真正需要的通常是 线性卷积。
线性卷积和循环卷积什么时候才会一致?条件是 FFT 点数足够大,能够完整装下这一块卷积的全部结果。设:
- 输入块长度为
L - FIR 滤波器长度为
M - FFT 点数为
N
那么至少要满足:
N >= L + M - 1
只有在这个条件成立时,频域乘法对应的 IFFT 结果才等价于这一块的线性卷积。否则就会发生下面这件事:
- 线性卷积本来应该有
L + M - 1个输出样本 - 但 IFFT 只能给出
N个样本 - 超出的那一部分不会消失,而是按模
N折返到前面 - 前面的样本因此被“尾巴”污染
这就是本文所说的混叠。需要特别强调一下,这里讨论的不是采样率不足造成的频谱混叠,而是循环卷积导致的时域混叠(time aliasing)。
下面这张图可以先建立整体直觉:
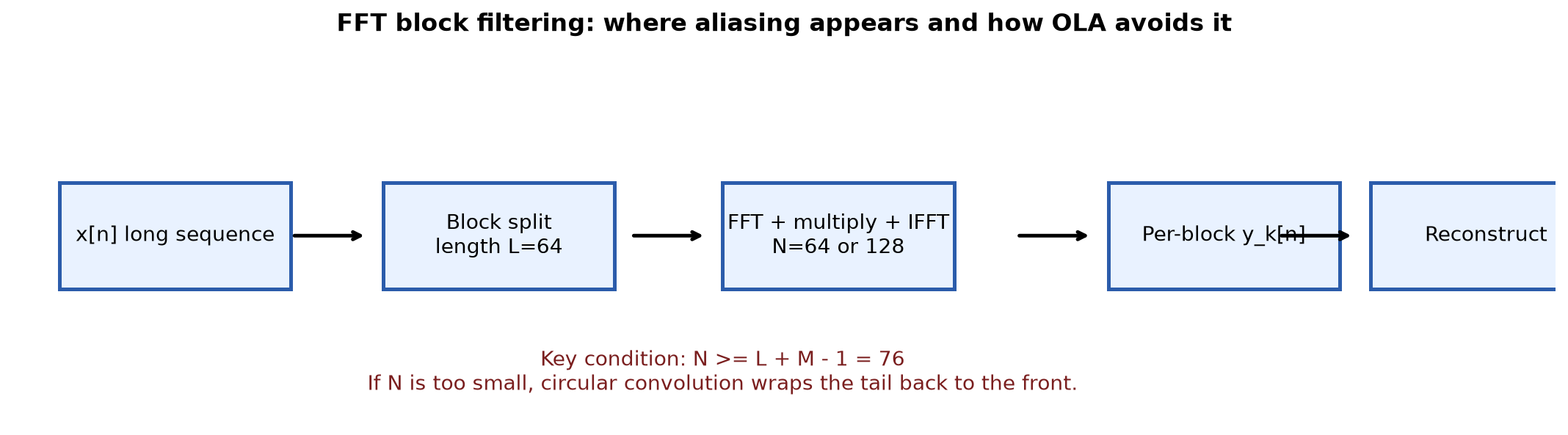
图中最关键的一句话就是:
当 N 不足以容纳 L + M - 1 个卷积结果时,末尾样本会折回到前部。
这也是为什么很多“按块 FFT 再 IFFT”的实现,看起来流程没问题,但边界总会出错。
2. 结合仿真说明混叠现象是怎么混叠的,末尾的数据是怎么折到前面污染数据的
为了让现象足够直观,本文配套脚本构造了一个测试信号:它同时包含低频分量、高频分量和两个瞬态脉冲,再通过一个短 FIR 滤波器。
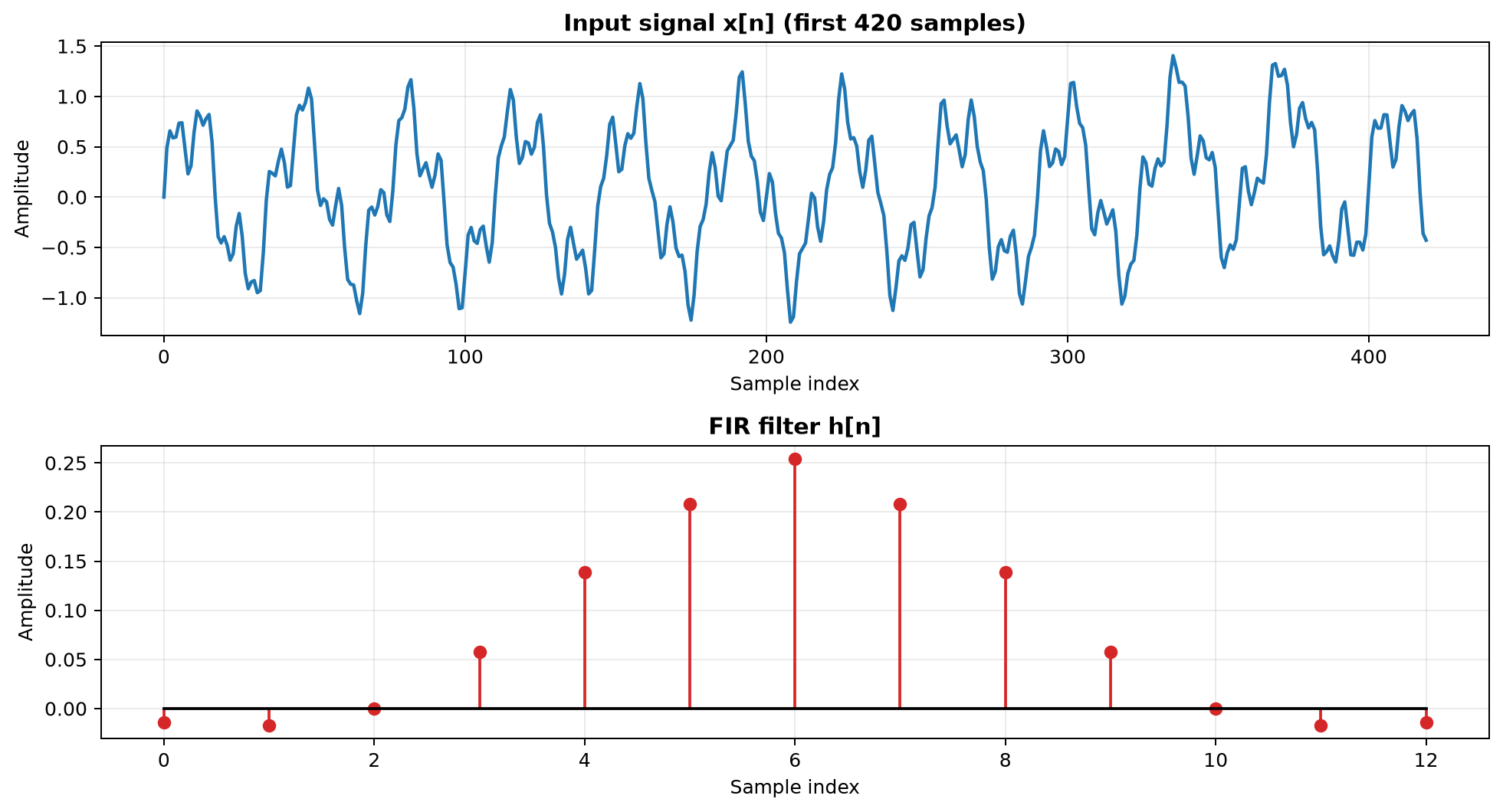
仿真参数如下:
- 输入信号长度:
0.6 s - 分块长度:
L = 64 - FIR 长度:
M = 13 - 错误示范的 FFT 点数:
N = 64 - 正确示范的 FFT 点数:
N = 128
这里为什么 N = 64 会出问题?因为这一块线性卷积的真实长度应该是:
L + M - 1 = 64 + 13 - 1 = 76
但现在 IFFT 只能输出 64 点,所以线性卷积的最后 12 点必然会回卷到前面,形成污染。
单块卷积的对比如下:
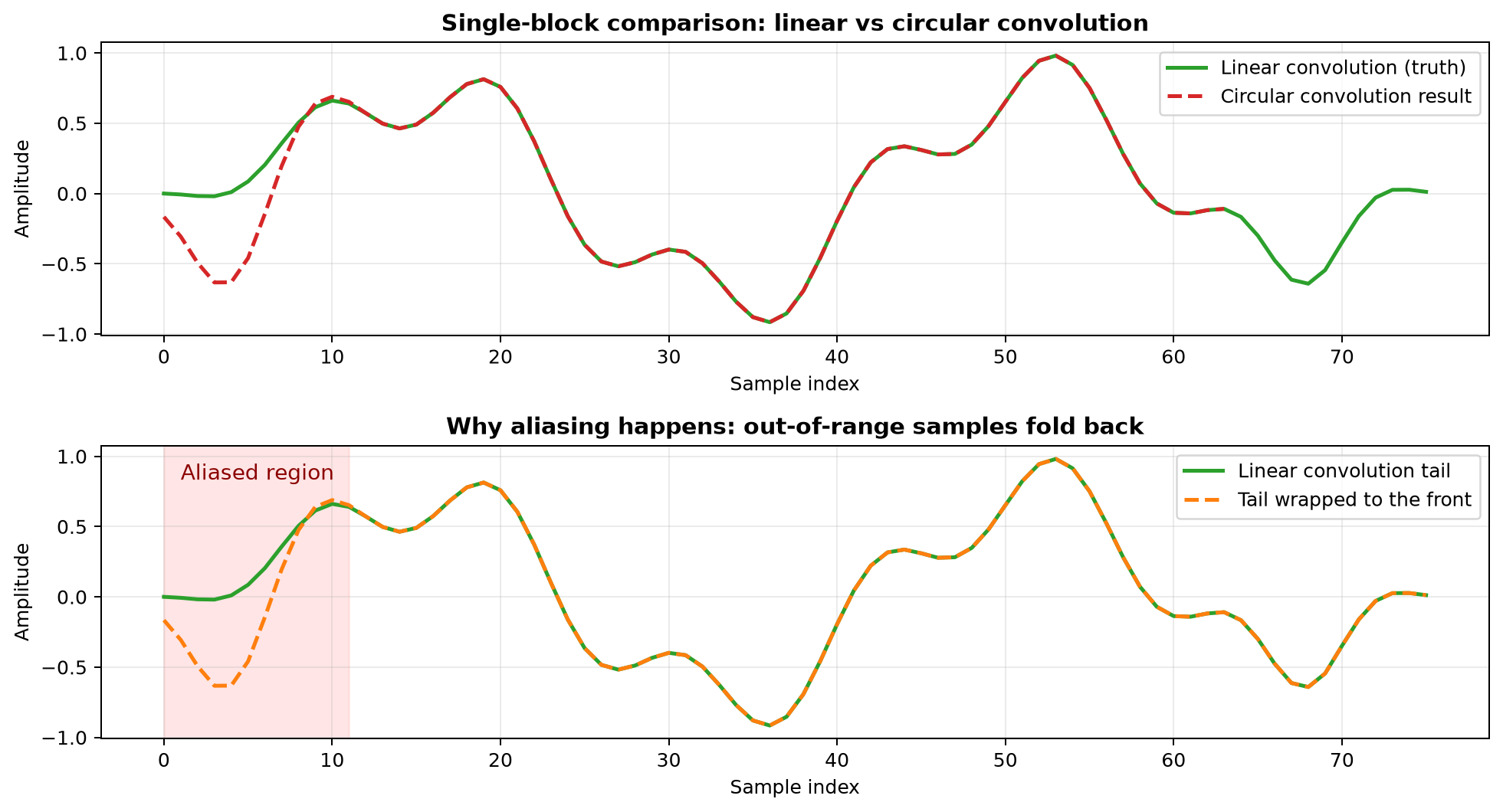
这张图可以分成两层来理解。
第一层,上半图:
- 绿色曲线是真实的线性卷积结果
- 红色虚线是直接做
64点 FFT 乘法再 IFFT 得到的循环卷积结果 - 两者明显不相等
第二层,下半图:
- 线性卷积本来有
76个样本 - 循环卷积只能保留
64个样本 - 超出的
12个样本按照模64折回 - 因此前面一段被额外叠加,出现失真
如果用公式写,循环卷积和线性卷积的关系可以写成:
y_circ[n] = Σ y_lin[n + rN]
它的含义很直接:
y_lin[n]是原本应该得到的线性卷积y_circ[n]是 FFT/IFFT 实际得到的长度为N的循环卷积- 所有超过
N-1的线性卷积样本,都会以N为周期折回并累加到前面
从工程角度看,这也是为什么简单写成下面这种流程会错:
- 把长序列按
L点分块 - 每块做 FFT
- 与滤波器频响相乘
- IFFT 回时域
- 把每块结果直接拼起来
问题在于,这里每块拿到的并不是已经处理好的线性卷积输出,而是一个带循环卷积边界效应的结果。如果你不额外处理重叠区,那么误差就会在每个块边界周期性重复。
全局结果对比如下:
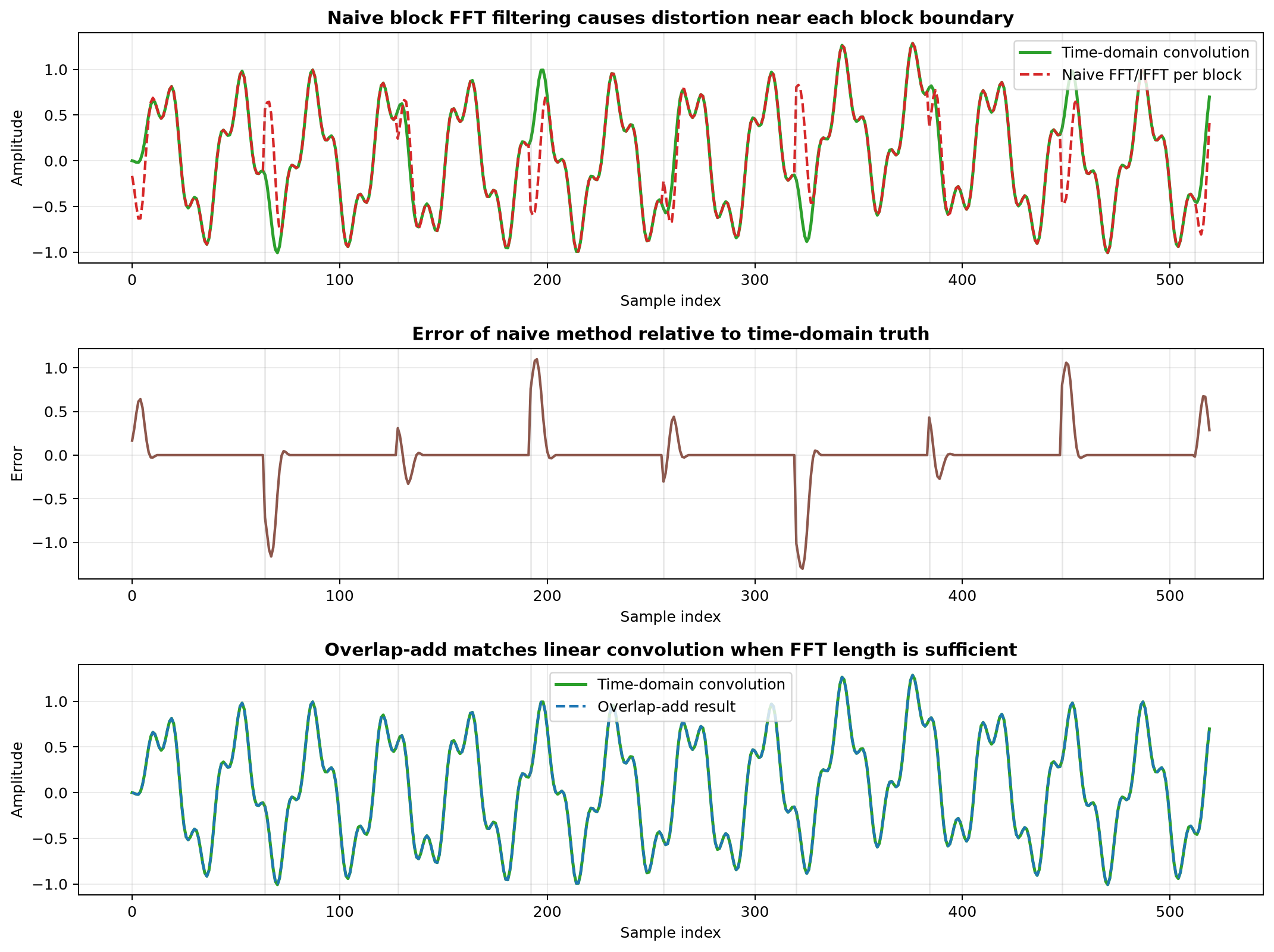
从图中可以看到:
- 错误方法的失真主要集中在各个块边界附近
- 误差具有明显周期性,因为每一块都在重复发生“尾巴折返”
- 这不是偶然数值误差,而是循环卷积与线性卷积不一致导致的结构性问题
本文配套脚本输出的误差指标如下:
block_len=64
filter_len=13
nfft_bad=64
nfft_good=128
condition_min_nfft=76
naive_max_abs_error=1.3024473136
naive_rmse=0.2235986890
ola_max_abs_error=0.0000000000
ola_rmse=0.0000000000
对应误差分布图如下:
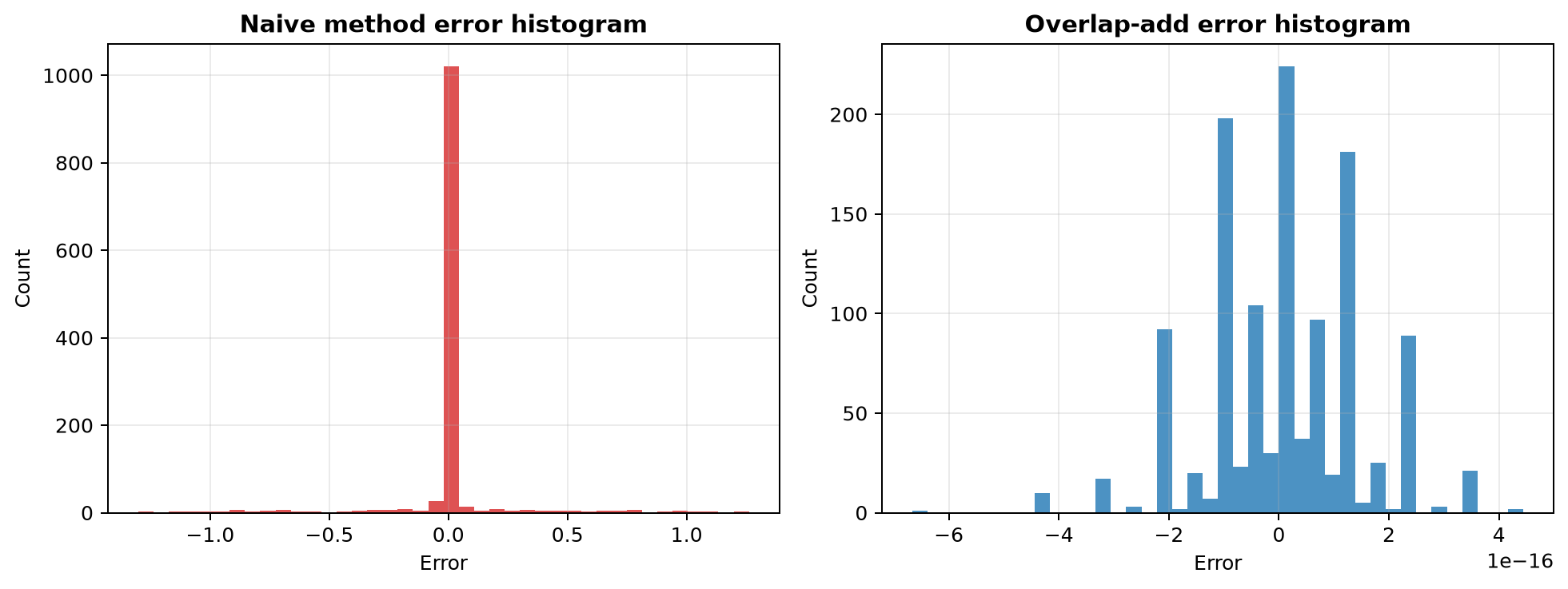
从结果上看,错误方法的最大绝对误差已经超过 1.3,说明块边界处的失真非常明显;而正确处理后的 OLA 结果则与时域直接卷积完全一致。
3. 结合仿真说明 overlap-add 方法是怎么解决这个问题的?
Overlap-Add 的核心思想并不复杂,关键是它把“错误折返”改成了“正确重叠相加”。
具体流程如下:
- 把长输入序列分成若干块,每块长度为
L - 对每一块做零填充,使 FFT 点数满足
N >= L + M - 1 - 在频域乘法后 IFFT,得到这一块完整的线性卷积结果
- 由于每块卷积长度变成
L + M - 1,相邻块输出天然会有重叠区 - 对这些重叠区做加法,恢复整体输出
这个方法为什么有效?因为它同时解决了两个问题:
- 块内:通过零填充保证 IFFT 长度足够,避免了循环折返
- 块间:通过 overlap-add 显式处理本来就存在的卷积重叠区
换句话说:
- 错误方法:把本该出现在后面的样本,错误地折回当前块前部
- OLA 方法:把本该与后续块叠加的样本,放在正确的时间位置做求和
这两者最大的区别不在于“有没有用 FFT”,而在于有没有把循环卷积重新组织成线性卷积。
从仿真图上看,第三行的 overlap-add 结果已经和时域直接卷积重合,这说明:
- 只要满足
N >= L + M - 1 - 并且按正确的位置做块间相加
- 频域快速卷积就可以和时域线性卷积完全等价
本文配套代码的核心函数如下:
错误示范是“每块做循环卷积后直接拼接”:
def naive_block_fft_filter(x, h, block_len, nfft):
outputs = []
h_fft = np.fft.fft(h, nfft)
for _, block in block_view(x, block_len):
padded = np.zeros(nfft)
padded[: len(block)] = block
y_block = np.fft.ifft(np.fft.fft(padded) * h_fft).real
outputs.append(y_block[: len(block)])
return np.concatenate(outputs)
正确做法是:每块零填充后,保留完整有效卷积长度,再做 overlap-add:
def overlap_add_filter(x, h, block_len, nfft):
h_fft = np.fft.fft(h, nfft)
out = np.zeros(len(x) + len(h) - 1)
for start, block in block_view(x, block_len):
padded = np.zeros(nfft)
padded[: len(block)] = block
y_block = np.fft.ifft(np.fft.fft(padded) * h_fft).real
valid = len(block) + len(h) - 1
out[start : start + valid] += y_block[:valid]
return out
对于工程实现,可以记住一个最重要的经验:
做块 FFT 卷积时,别只关心频域乘法,更要关心边界怎么还原成线性卷积。
FFT 提供的是计算效率,OLA 提供的是边界正确性。两者缺一不可。
4. 简要解释一下 OLA 和 WOLA 的区别
虽然名字很像,但 OLA 和 WOLA 关注的问题并不完全一样。
4.1 OLA 是什么
OLA(Overlap-Add)主要用于快速卷积 / 分块 FIR 实现。它的出发点是:先把长信号分块,每块在频域里完成卷积,再把块输出的重叠部分相加,它主要解决的问题是:如何把每块的循环卷积结果重构成正确的线性卷积,如何在保证计算效率的同时,正确处理块边界,所以 OLA 更偏向“卷积实现方法”。
4.2 WOLA 是什么
WOLA(Weighted Overlap-Add)可以理解为“带窗函数的 Overlap-Add”。它更常见于:STFT/ISTFT、子带处理、语音增强、频谱修改、音频编解码。它的典型流程是:对每帧先乘分析窗,做频域处理,IFFT 后再乘合成窗,最后通过带权重的 overlap-add 重构时域信号。
WOLA 主要关注的是:分帧分析与重构时的平滑拼接,降低频谱泄漏和块边界不连续,在时频域处理之后实现低失真重建,所以 WOLA 更偏向“时频分析重构框架”。
4.3 二者的核心区别
- OLA 的重点是:解决快速卷积中的线性卷积重构问题
- WOLA 的重点是:解决时频域处理中的加窗、重构和平滑拼接问题
它们都包含“overlap-add”这个动作,但应用场景并不一样,针对的问题也不一样。
结论
本文总结:
- FFT 频域乘法再 IFFT,天然得到的是循环卷积,而不是线性卷积。
- 当
N < L + M - 1时,线性卷积尾部会按模N折返到前面,形成时域混叠。 - Overlap-Add 通过“零填充 + 正确叠加重叠区”,把频域块处理重新组织成正确的线性卷积。
- OLA 更偏快速卷积实现,WOLA 更偏时频分析重构,它们名字相近,但关注点不同。
附:运行方式
在当前目录执行:
python fft_overlap_add_demo.py
脚本会生成:
article_assets/01_principle_diagram.pngarticle_assets/02_signal_and_filter.pngarticle_assets/03_single_block_aliasing.pngarticle_assets/04_output_comparison.pngarticle_assets/05_error_histograms.pngarticle_assets/metrics.txt